SINGAPORE, Aug. 15, 2025 /PRNewswire/ — The SkyWork AI Technology Release Week officially kicked off on August 11. From August 11 to August 15, one new model was launched each day for five consecutive days, covering cutting-edge models for core multimodal AI scenarios.
As of now, Skywork has already launched the SkyReels-A3, Matrix-Game 2.0, Matrix-3D, Skywork UniPic 2.0, and Skywork Deep Research Agent models. On August 15, the Mureka V7.5 model was officially launched, marking the successful conclusion of the SkyWork AI Technology Release Week.


{kind=link}
Mureka V7.5 has reached new heights in its interpretation of Chinese songs. The model demonstrates significant improvements not only in vocal timbre and instrumental techniques but also in lyric articulation and emotional expression.
First, building on its robust understanding of Chinese musical styles and elements, Mureka’s comprehension model delivers profound insights — spanning traditional folk songs, operatic pieces, classic Mandopop hits, and contemporary folk music. This deep mastery of musical diversity and cultural nuances allows the model to precisely capture and express the unique artistic essence and emotional subtleties in both interpretation and generation of Chinese music.
Second, to achieve more authentic and emotionally expressive AI-generated vocals, we have significantly enhanced our ASR technology, tailoring it to musical characteristics and establishing it as a powerful complement to our comprehension module. This technology analyzes vocal performances at a granular level, going beyond basic lyric recognition to examine performance techniques including breath control, emotional dynamics, and articulation nuances. By intelligently parsing musical phrases, detecting natural breathing points, and identifying structural pauses – while maintaining precise section recognition – it delivers synthesized vocals with unprecedented structural coherence and perceptual realism.
The captured high-resolution vocal data is fed back into the generative model, significantly enhancing the synthesized vocals’ naturalness, breath realism, and emotional expressiveness while reducing mechanical artifacts. This enables AI-generated songs to achieve human-like fluidity — particularly when reproducing the distinctive rhythmic phrasing and breath control unique to Chinese vocal music.
This unique combination of culturally-informed expertise and our song-optimized ASR technology’s granular insights constitutes our definitive competitive advantage in Chinese music generation.
Mureka V7.5 not only “understands” melodic and rhythmic production requirements but also deeply interprets and replicates the nuanced emotions and artistic expressions inherent to different cultural contexts — especially Chinese music. This capability provides a robust technical foundation for generating music that is both culturally authentic and aesthetically compelling, balancing artistic depth with lifelike realism.
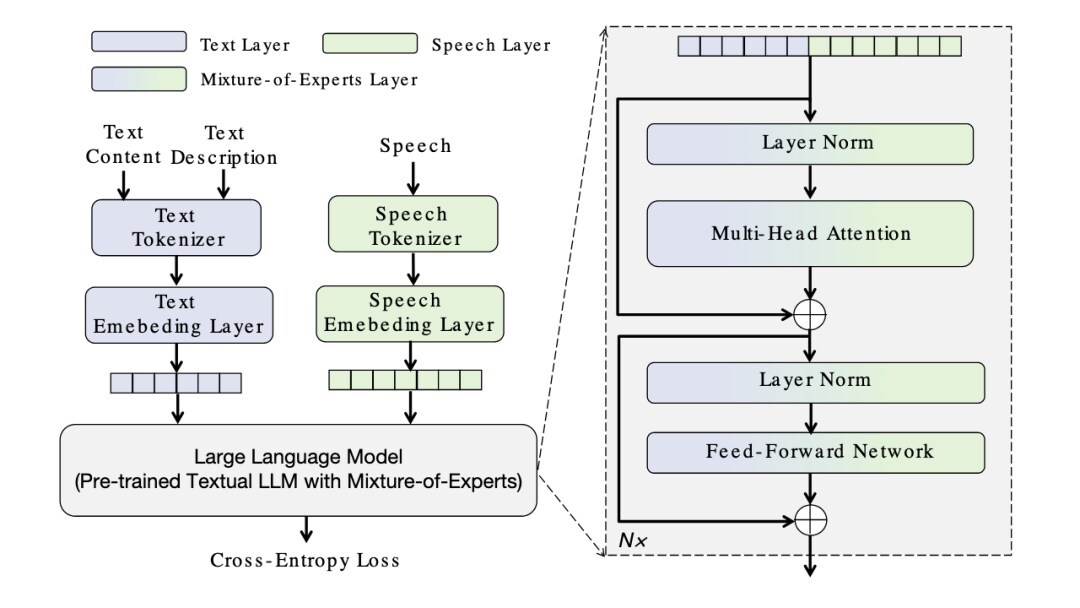
For voice models, the Skywork voice team has launched MoE-TTS — the first Mixture-of-Experts-based character-descriptive text-to-speech framework.
As a novel TTS framework specialized for out-of-domain descriptions, this technology enables precise control over vocal characteristics via natural language inputs (e.g., “a crystal-clear youthful voice with magnetic vocal fry”). Despite using only open-source training data, it achieves character voice consistency on par with or superior to proprietary commercial systems.
In recent years, descriptive TTS has demonstrated significant potential across virtual assistants, audio content creation, and digital humans. However, academic research has long been constrained by scarce description datasets and poor model generalization to open-domain semantics. These limitations frequently lead to mismatched vocal outputs — particularly when interpreting figurative language such as metaphors or analogies.
The introduction of MoE-TTS presents a promising solution to this core challenge. The framework innovatively integrates a pre-trained textual large language model (LLM) with specialized speech expert modules, employing dedicated experts for each modality. Its transformer architecture incorporates novel modality routing that enables independent optimization of text and voice pathways without interference. While keeping text parameters frozen, the framework achieves efficient cross-modal alignment, thereby delivering generalization capabilities with “zero knowledge degradation.”

In comprehensive evaluations spanning both in-domain and out-of-domain description test sets, MoE-TTS was benchmarked against leading proprietary TTS models across six dimensions. Results reveal MoE-TTS’s statistically significant advantages in acoustic control metrics — particularly Stylistic Expressiveness Alignment (SEA) and Overall Alignment (OA) — with these precision gains directly explaining its superior performance in complex linguistic description matching.
The release of MoE-TTS provides academia with the first reproducible out-of-domain TTS solution while conclusively demonstrating the efficacy of modality-decoupled architectures with frozen knowledge transfer in speech synthesis. This breakthrough marks a critical step toward transitioning the industry from “closed-label control” systems to “natural language free-form control” — a paradigm shift that will redefine user experiences across digital humans, virtual assistants, and immersive content creation platforms.
MoE-TTS is currently under active iteration, with plans to integrate it into the Mureka-Speech platform as a foundational model for character voice synthesis. This will provide global developers and creators with open, efficient, and customizable descriptive speech synthesis capabilities.
Experience the all-new V7.5 Model
Unlock infinite possibilities in music creation!
Try it now: www.mureka.ai