SHANGHAI, April 24, 2026 /PRNewswire/ — United Imaging Intelligence (UII) has unveiled uAI NEXUS MedVLM, a pioneering Medical Video Large Language Model that delivers unprecedented spatial and temporal precision in clinical environments.
UII is fully open-sourcing the model and introducing a new comprehensive benchmark for industry-wide evaluation. The research has been accepted by CVPR 2026, one of the top AI conferences, underscoring its recognition by the global computer vision community.

uAI NEXUS MedVLM is built on a monumental dataset comprising 531,850 video-instruction pairs across 8 clinical scenarios, including robotic surgery, laparoscopic procedures, endoscopy, open surgery, and nursing care.
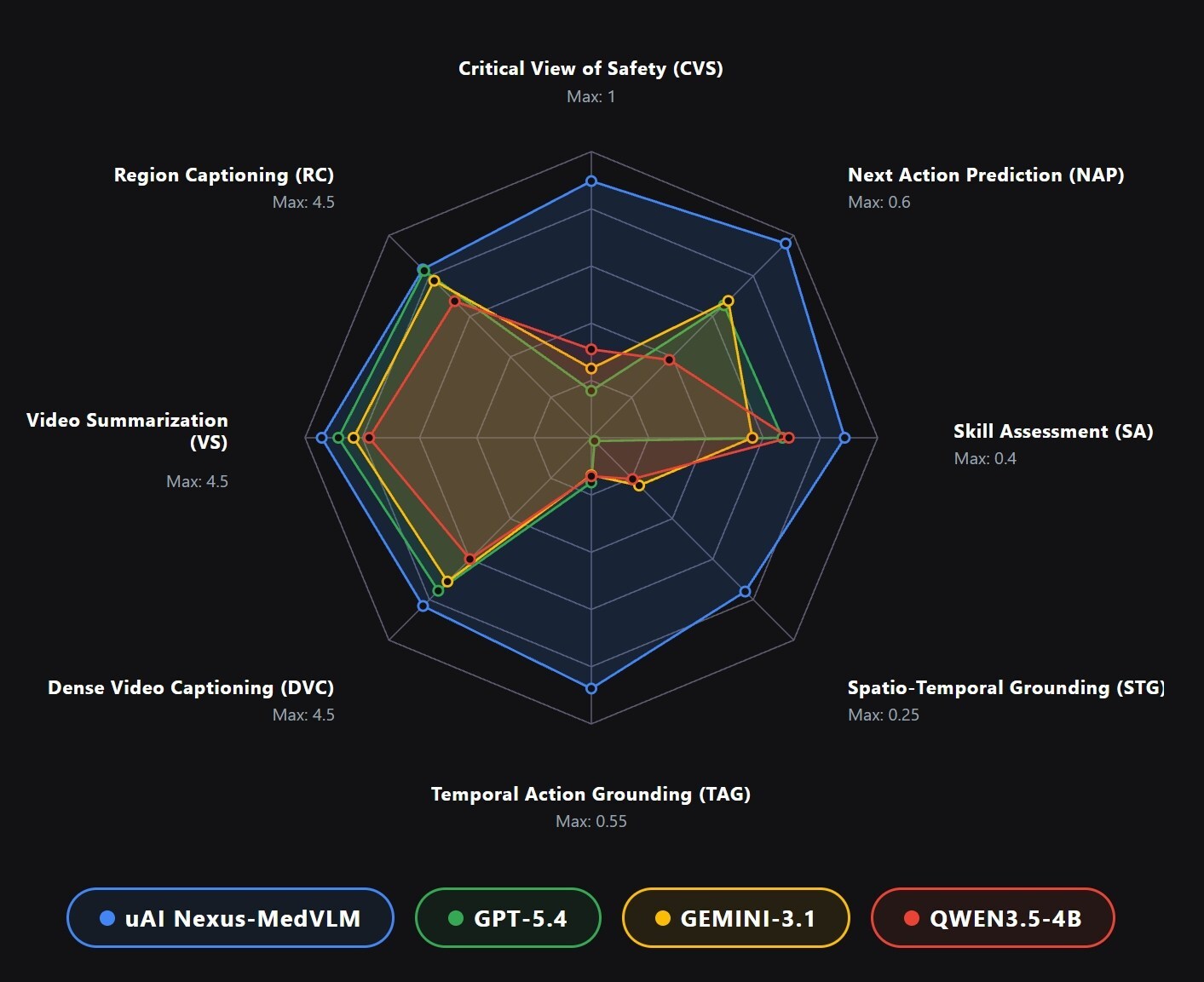
With only 4B/7B parameters, uAI NEXUS MedVLM significantly outperforms leading general-purpose foundation models, including GPT-5.4 and Gemini 3.1, across key medical video tasks. It achieves 89.4% accuracy in surgical safety assessment, compared to GPT-5.4 (1.8%) and Gemini 3.1 (10.1%). In spatio-temporal action localization, it delivers up to 14× higher mIoU than GPT-5.4 and 4× higher than Gemini 3.1. For video report generation, it scores 4.2 out of 5, substantially surpassing GPT-5.4 (2.5) and Gemini 3.1 (2.4).
(Source: The above performance statistics are from the research paper: https://arxiv.org/abs/2512.06581)

The statistics shown in this radar chart are from the research paper: https://arxiv.org/abs/2512.06581
Launching a Global Open Challenge to Accelerate Collaborative Innovation
To advance medical video LLM development, UII has launched a phased rollout of its MedVidBench dataset, beginning with the open-source release of 6,245 rigorous benchmark test samples. Spanning eight diverse surgical datasets, this initiative marks a global first in terms of both scale and clinical precision.
Developers can evaluate their models on a unified leaderboard, where submissions are automatically assessed against private ground truth. Results are reflected in a continuously updated global ranking, enabling transparent and comparable performance evaluation across models.

UII invites AI researchers, developers, and healthcare institutions worldwide to participate in this open challenge and help advance medical video intelligence through collaborative innovation.
Project Page: https://uii-ai.github.io/MedGRPO/
Advancing Intelligence Across the Full Spectrum of Medical Video Tasks
Medical video understanding has long remained one of the most formidable frontiers in artificial intelligence—demanding microscopic spatial awareness, complex temporal logic, and uncompromising clinical accuracy. Historically, progress has been paralyzed by the severe scarcity of clinical data and the prohibitive cost of expert annotation.
UII has shattered this bottleneck. By engineering a massive, frame-by-frame annotation framework across diverse clinical videos, we have rigorously mapped critical attributes: instrument trajectories, spatial positioning, precise surgical actions, and crucial risk indicators. This unprecedented data foundation equips uAI NEXUS MedVLM with a complete, robust clinical intelligence stack.
Built on this foundation, the model seamlessly integrates perception, reasoning, and decision-making. It delivers highly accurate spatio-temporal localization of instruments and automated procedural recognition, applying advanced reasoning to transform complex video sequences into structured clinical reports, regional descriptions, and rapid workflow summaries. Moving beyond passive observation, it elevates these insights into active decision-making that supports next-step prediction, surgical skill assessment, and comprehensive safety risk evaluation.
Translating AI Innovation into Real-World Clinical Impact
Built for clinical deployment, uAI NEXUS MedVLM enables more informed decision-making and data-driven quality control across surgical workflows, while reducing the learning curve for clinicians and improving training efficiency and consistency.
Looking ahead, uAI NEXUS MedVLM can serve as the core perceptual and cognitive engine for embodied AI operating in the physical world. Together, they form a closed-loop system of visual perception, cognitive reasoning, and physical execution, advancing toward a more automated, standardized, and intelligent healthcare ecosystem.

{kind=link}